
统计字数的几种方法
一般情况下,统计的时候,Emoji 是算成一个数,但 ES6 之前的 api 是会把这种字符算成多个。
1. 最简单但有明显问题的 String.prototype.length
'中文'.length // 2
'𠮷'.length // 2
'💖'.length // 2
'🙋♂️'.length // 5
console.log('\u4E2D\u6587') // 中文
console.log('\uD83D\uDC96') // 💖
console.log('\uD842\uDFB7') // 𠮷
console.log('\uD83D\uDE4B\u200D\u2642\uFE0F') // 🙋♂️
最后一个 🙋♂️ 的长度有 5 个字符,中间有一个零宽字符 \u200D,能把两个Emoji合并成一个。 最后有一个 \uFE0F 是一个变体选择器。 可以看文末参考链接。
下面是一个黑色皮肤的举手 Emoji:
console.log("\uD83D\uDE4B\uD83C\uDFFF\u200D\u2642\uFE0F") // 🙋🏿♂️
这里面的 \uD83C\uDFFB 代表的是黑色皮肤,如果是 \uD83C\uDFFB 代表的是白色皮肤,可以看参考文末链接。
2. 使用 Array.from
Array.from('中文').length // 2
Array.from('𠮷').length // 2
Array.from('💖').length // 1
Array.from('🙋♂️').length // 4
这里会把🙋♂️ 分拆成四个部分 ["\uD83D\uDE4B", "\u200D", "\u2642", "\uFE0F"]
console.log("\uD83D\uDE4B") // 🙋
console.log("\u200D") // \u200D
console.log("\u2642") // ♂
console.log("\uFE0F")
所以使用 Array.from 也不是一个比较好的统计字数的方法。
3. 使用正则表达式
ES6 之后给 REGEX FLAGS 添加了 u 标识位,对 Unicode 更加友好的支持。比如:
'𠮷'.match(/\S/g).length // 2
'𠮷'.match(/\S/gu).length // 1但在处理组合的 Emoji 的时候,还是没有比较好的处理:
'🙋♂️'.match(/\S/gu).length // 4后来找了一个字数统计正则的例子:
const ASTRAL_REGEX = /\ud83c[\udffb-\udfff](?=\ud83c[\udffb-\udfff])|(?:[^\ud800-\udfff][\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]?|[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|(?:\ud83c[\udde6-\uddff]){2}|[\ud800-\udbff][\udc00-\udfff]|[\ud800-\udfff])[\ufe0e\ufe0f]?(?:[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|\ud83c[\udffb-\udfff])?(?:\u200d(?:[^\ud800-\udfff]|(?:\ud83c[\udde6-\uddff]){2}|[\ud800-\udbff][\udc00-\udfff])[\ufe0e\ufe0f]?(?:[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|\ud83c[\udffb-\udfff])?)*/g
'𠮷'.match(ASTRAL_REGEX).length // 1
'🙋♂️'.match(ASTRAL_REGEX).length // 1
Benchmark
写了一个脚本分别测试原生 length、Array.from、/\S/gu、REGEX_UNICODE_CHARACTER 测试判断的长度时间:
const UNICODE_WORD_REGEX = /[\u00ff-\uffff]|\S+/g
const UNICODE_CHARACTER_REGEX = /\S/gmu
const UNICODE_CHARACTER2_REGEX = /\ud83c[\udffb-\udfff](?=\ud83c[\udffb-\udfff])|(?:[^\ud800-\udfff][\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]?|[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|(?:\ud83c[\udde6-\uddff]){2}|[\ud800-\udbff][\udc00-\udfff]|[\ud800-\udfff])[\ufe0e\ufe0f]?(?:[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|\ud83c[\udffb-\udfff])?(?:\u200d(?:[^\ud800-\udfff]|(?:\ud83c[\udde6-\uddff]){2}|[\ud800-\udbff][\udc00-\udfff])[\ufe0e\ufe0f]?(?:[\u0300-\u036f\ufe20-\ufe23\u20d0-\u20f0]|\ud83c[\udffb-\udfff])?)*/g
const TIMES = 100000
const str = Array.from(new Array(10)).reduce((s) => s + '中文𠮷?précédantお客様の💖🙋♂️', '')
let count1 = 0
console.time('length')
for (let i = 0; i < TIMES; ++i) {
count1 += str.length
}
console.timeEnd('length')
console.log('count1 length:', count1)
let count2 = 0
console.time('array from')
for (let i = 0; i < TIMES; ++i) {
count2 += Array.from(str).length
}
console.timeEnd('array from')
console.log('count2 length:', count2)
let count3 = 0
console.time('regex unicode')
for (let i = 0; i < TIMES; ++i) {
count3 += str.match(UNICODE_CHARACTER_REGEX).length
}
console.timeEnd('regex unicode')
console.log('count3 length:', count3)
let count4 = 0
console.time('regex2')
for (let i = 0; i < TIMES; ++i) {
count4 += str.match(UNICODE_CHARACTER2_REGEX).length
}
console.timeEnd('regex2')
console.log('count4 length:', count4)
通过测试 190 个字,循环 100000 遍,得到执行结果如下,使用 UNICODE_CHARACTER2_REGEX 是一个折衷方案中最好的方法。
| 使用方法 | 计算长度 | 耗费时间(ms) |
|---|---|---|
| String.prototype.length | 25000000 | 3.134 |
| Array.from | 22000000 | 2635.567 |
| UNICODE_CHARACTER_REGEX | 22000000 | 916.429 |
| UNICODE_CHARACTER2_REGEX | 19000000 | 748.209 |
UNICODE_CHARACTER2_REGEX 统计出的 19000000 才是正确的。
参考
- 肤色编码: https://emojipedia.org/modifiers/
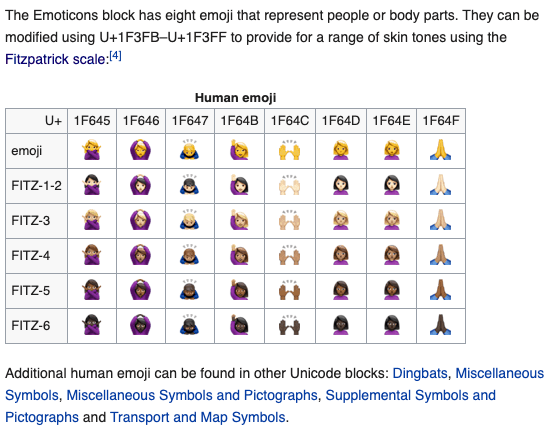
这里的 FITZ-(1~5) 就是不同的五种肤色,从 \u1F3FB – \u1F3FF 共五个。
- 变量选择器:https://en.wikipedia.org/wiki/Emoticons_(Unicode_block)
常见的有:
- "变量选择器-15"(VARIATION SELECTOR-15, 简写VS-15):
- "变量选择器-16"(VARIATION SELECTOR-16, 简写VS-16):
- UNICODE_CHARACTER2_REGEX 来自这里: https://github.com/sallar/unicode-astral-regex
- 比较详细的介绍 Unicode 编码:https://segmentfault.com/a/1190000017782406 。这里面就会介绍 UNICODE_CHARACTER2_REGEX 这种这么长的正则是通过专门的库生成的。